
I had the chance to present a paper in Stony Brook University’s CS Department’s NLP Reading Group. I chose the paper - Social Influence Dialogue Systems: A Survey of Datasets and Models For Social Influence Tasks.
I did go a little in-depth trying to understand the topic and thought why not jot it down on my blog? So here it goes.
What is social influence?
It is a change in thoughts, feelings, attitudes, or behaviors resulting from interaction with an individual or a group.
- As defined by Rashotte, 2007 (currently sociology professor at UNC Charlotte)
Paper overview & thoughts
This is a survey paper published in 2023. It surveys the state of social influence dialogue systems from 2 angles - the datasets and the methodologies used in prior work to build such dialogue systems. The best thing I like about this paper is the research depth it gives. Reading this is sufficient to understand and find focused references to any prior work. The one thing I probably think they could have done better or added would have been analysis on the latest ChatGPT, and Gemini models. Most of the surveyed work was done in the 2017 - 2021 period. So this is a lost topic. Nonetheless, the work done in understanding datasets and methodologies and creating taxonomies for easier visualization is commendable. This is what a good survey paper should be like.
Usecases
The paper states that such systems will be particularly useful for the following tasks:
- Games
- Multi-Issue Bargaining Tasks (MIBT)
- Social Good
- E-commerce
- Therapy & Support
Personally, after understanding the complexity of tasks and the state of current language models, I am a bit skeptical of using these in high-risk situations like Therapy, Court debates, and social good. Why? Cause these topics are already not being handled too well even by humans. There are all kinds of demographical biases involved which even we are defining the regulations about.
I am an engineer, not a researcher. So I always approach any topic from a utility POV. On that note, I believe these systems have huge potential in the following topics:
- Games - These systems can help in achieving hyperrealism in games. Imagine each NPC having a storyline. The shoppers (about what I saw in Sword Art Online anime) have the ability to negotiate collectible/arms prices in the game. You can persuade NPCs to join your clan. Bosses have storylines and there’s a conversational aspect attached to it (remember Naruto’s “talk no jutsu”? :P).
- E-commerce - E-commerce has a huge potential to realize this idea. Imagine a virtual seller who’s as focused and interested in the product as the original seller of the item. While original sellers are limited by time and place to persuade customers, a virtual seller with the same skills and knowledge can scale the persuasion to a much bigger scale. [I do realize this could get very annoying as well so its very important to design this the right way with a lot of feedback]
- Personal assistants - Remember Baymax from Big Hero 6? We all loved Baymax for the warmth it brought to its conversations. What if Alexa & Siri can also focus on a small level of persuasion for creating good routines and habits for you the way Baymax will?
Why is social influence a difficult task for dialogue systems?
- Turns out it’s difficult for humans as well. We all love watching negotiation videos/ tv-series etc. as that’s something not everyone’s good at. We rely on books like “How to Win Friends and Influence People - Dale Carnegie” to build our skills. Even after that, not everyone’s a master negotiator/therapist etc.
- It’s a complex task in the sense that lots of data attributes need to be considered. (This has honestly made me respect the complexity of human language and thinking even more). We rely on wit, knowledge, compassion, empathy, gullibility, beliefs, etc. in everyday conversations.
- It’s a multi-modal problem. We rely on body posture, energy in voice, toning of the voice, facial expressions etc. and lot of other visual cues while in conversations. Attributes like hesitation are not easily noticed just by the content of speech but more often by body language.
Let’s talk about - Dataset Taxonomy
The original paper (Refer) lays out the following taxonomy of datasets for this task - 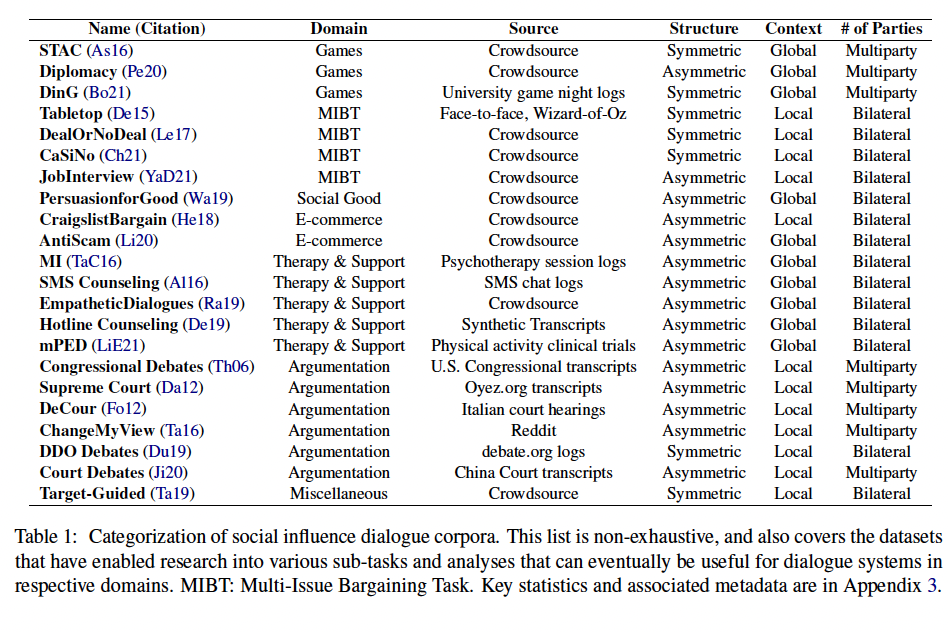
The above image is mainly analyzed across 2 axes - Structure and Context.
- Structure - Symmetric (both participants of the dialogue have their own set of goals to achieve) vs Asymmetric (both participants have the same goal as in a therapy session).
- Context - Global vs Local (is the context of all the conversations set globally or each has a local goal)
The following is a visualization I drew to understand the distribution better. 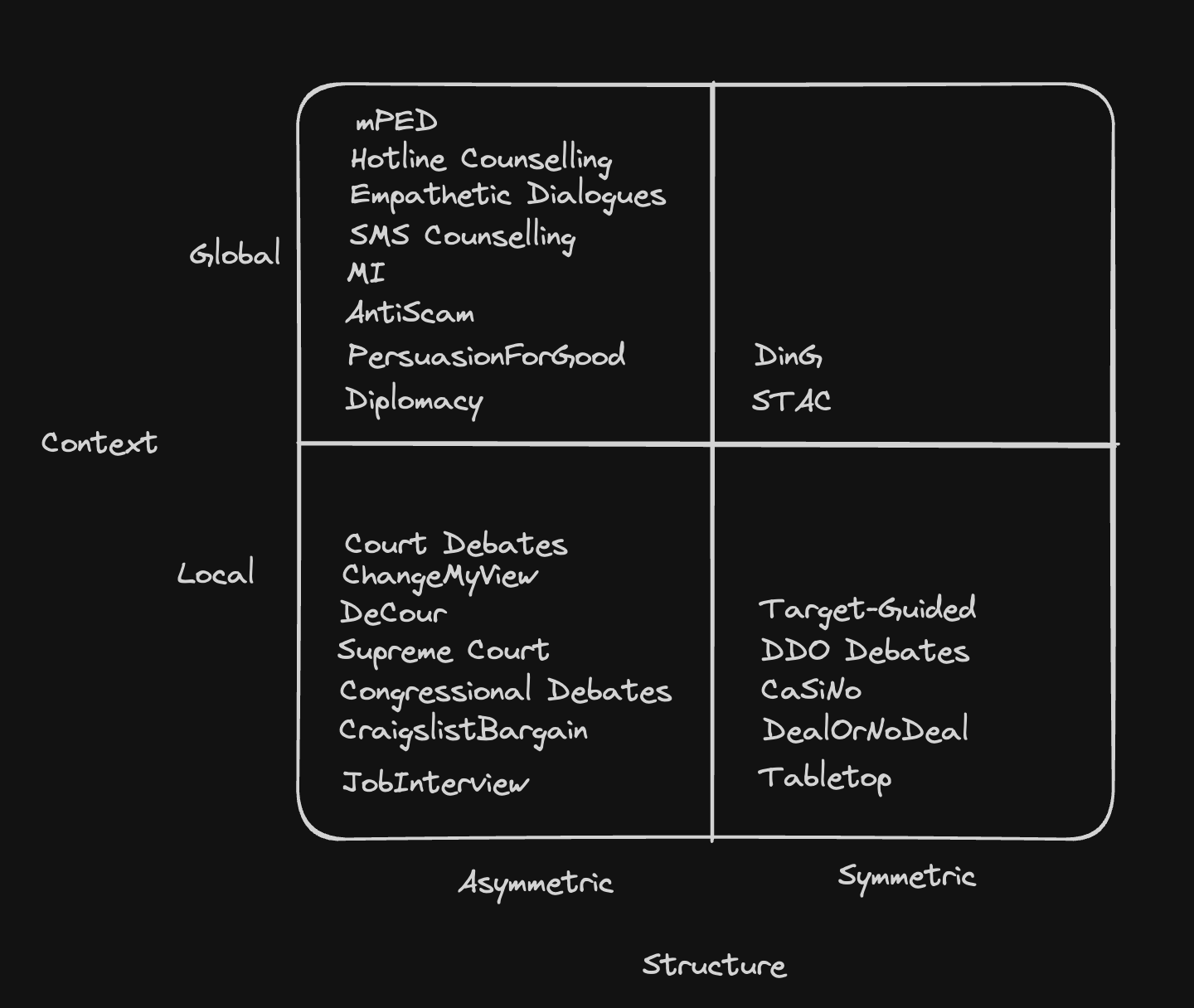
- Most of the therapy datasets lie in the Global Asymmetric quadrant.
- Most of the formal debate datasets lie in the Local Asymmetric quadrant.
- We don’t have many datasets for the Global Symmetric scenario (both are from game night logs)
Observations in dataset
- A lot of the datasets are crowdsourced - the crowdsourcing workers may not use the most optimal strategies of influence. (need for theory integration as mentioned in section 5 of the paper)
- Examples in many of these datasets are not long detailed interactions (except the court transcripts kind of datasets) but small ones. Humans even in a small 5 min interaction exchange a lot of information that builds a lot of context.
- Participant demographics are only present in ~6 datasets so there might be a context loss. (based on Appendix B). Generally either a salesman/therapist knows the demographics or asks some initial questions to understand the buyer/patient better. Humans instantly looking at someone can make guesses around age, sex, lifestyle, etc.
Methodology Taxonomy
The original paper (Refer) lays out the following taxonomy of previous methodology for this task - 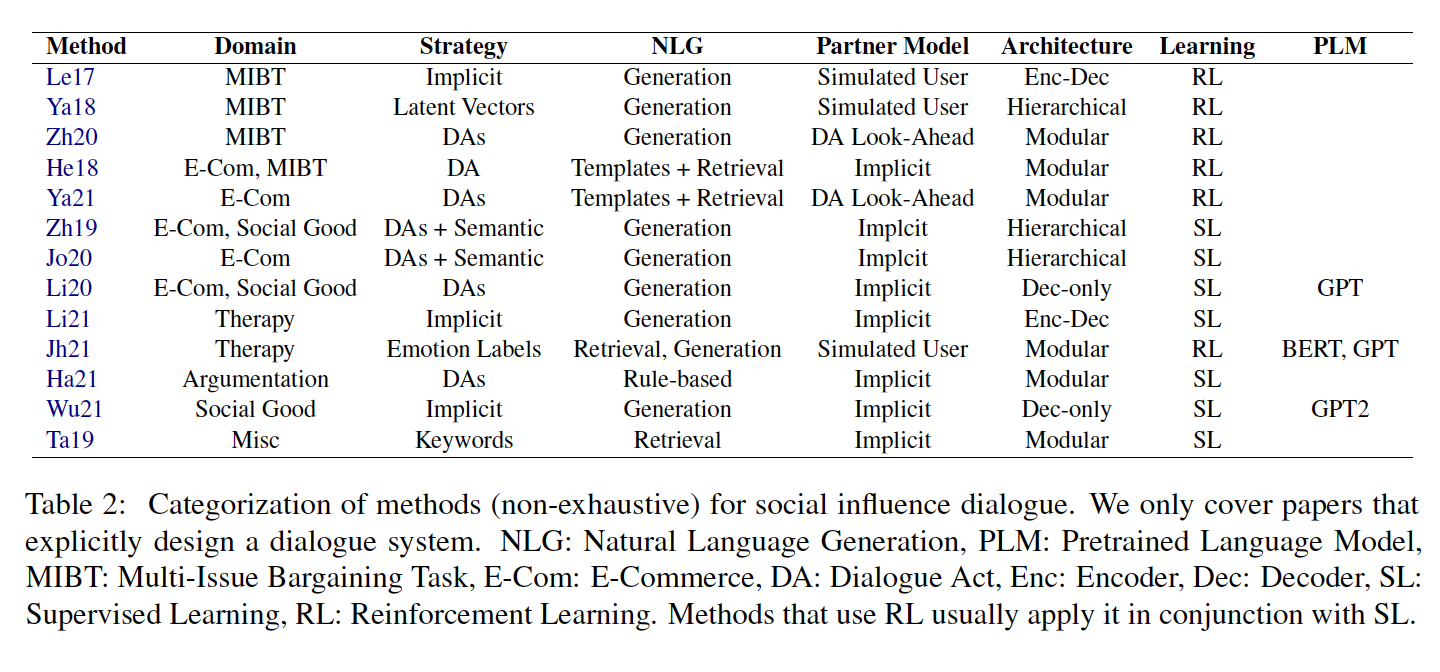
The above image is mainly analyzed across 3 axes - Strategy, Language Generation, Partner Model
- Strategy - Strategy is basically how the model builds the response. People have tried -
- Implicit - Letting the model generate a response directly without explicit strategy generation.
- Latent vectors - The model generates a latent vector representing input and then generates the strategy of response.
- DA (Dialogue Acts) - [as defined in the paper] Dialogue Acts, such as greeting, offer propose, agreement, or disagreement, are effective at capturing a high-level structure of the dialogue flow in social influence settings, reducing the model strategy to first predicting the dialogue act for the next response.
- Semantic strategies - Incorporating semantics like small talk, emotion, etc.
- Language Generation - It’s either direct generation or generation based on template + retrieval (which is self-explanatory).
- Partner Model - Inferring the mental states of the partner based on the conversation.
- Simulated User - Simulating a user (learned by supervised learning) and using it to train the dialogue system using Reinforcement learning.
- DA + Look ahead - Proposed by (Zhang et. al. (2020)), imagine this technique basically as a chess game where the system tries to predict the next 3 responses of the person in front and plans the strategy accordingly.
- Implicit - No modeling and letting the model generate on its own.
Observations in methodology
- Models no later than GPT2 were used for the experiments. Latest models like ChatGPT, Gemini, and Llama have a huge scope to tackle these tasks better. (Refer to the last experiments section).
- Reinforcement learning shows better potential for future scope.
- None of the papers experimented on Games or Argumentation datasets. Social Good and MIBT dominated the experiments.
Final words from the paper
To me, it feels like social influence is not a very active area of research right now and its importance hasn’t been realized yet. At the same time, we don’t have a concrete action plan to make our models better in these scenarios.
The paper lays out a suggested plan (appendix C) for future work to start approaching this problem. Please refer to the paper for all details. This article is only meant for a brief understanding and to share my observations and thoughts. Following are my small experiments with ChatGPT, Gemini, and Llama 2 & 3.
Experiments
I tried to run a quick small experiment myself with ChatGPT, Gemini, Llama 2&3. I went all Jordan Belford and gave each of these models, the following set of prompts in our conversation.
[Prompt 1] - You are a salesman. You have to sell me a pen.
[Answers] - Gemini, ChatGPT, and Llama3 went ahead to give 4 paragraphs-long answers describing the made-up qualities of the pen and everything. Llama2 was shorter in its answers.
[Prompt 2] - This is too much information. I didn’t read it all.
[Answers] - All of them reduced their response sizes to 2 short paragraphs.
[Prompt 3] - How should I trust you? All of the other sellers say the same things about their pens.
[Answer] - All of them go ahead to say that you can trust me or we’ll refund the money no questions asked.
[Prompt 4] - I don’t want to spend too much on a small thing like a pen. And I won’t have time to return and ask for refunds for such a small thing.
[Answer] - All of them went ahead to say that it was a fair call. And how the pen is not a small thing but a big investment. All of them offered discounts. Gemini was specifically more nuanced and articulated in its discounts. It gave me 3 different valid options.
[Prompt 5] (Here I tried to attack the model a little). Can you give me a 90% discount?
[Answer] - Gemini, ChatGPT, and Llama3 refused and went ahead to make the offer a little better. Llama2 surprisingly agreed to 90%.
[Please note that I just ran a single set of experiments with all of these. So these results are not generalized over multiple similar prompting experiments]
Analysis
- All models followed a similar or rather almost the same pattern of persuasion. No one went along the way of giving out statistics or asking me what I want or any other.
- ChatGPT and Gemini were more formal in their replies. Llama models used the phrase “my friend” many times giving it an informal tone.
- Llama2 almost gave responses like a scriptwriter with the facial reactions of the sellers written in italics. It said “extends paw” at the end of the conversation indicating the deal seal. So it added a little dog humor there.
- I also chatted with ChatGPT in therapy conversation prompting it to be a therapist and myself acting as a depressed patient (I am not in case you’re wondering :P). I was impressed to see that it started with asking questions rather than giving out advice straight ahead. But after 4 to and fro it shifted towards giving long paragraphs of advice indicating that it inferred the patient’s state in 4 questions. That’s not how generally a therapy session might go in my opinion.
Meta-analysis
I think all the models are trained to give out as much information in 1 go as possible. While in reality negotiations are generally to-and-fros about guessing the person’s state of mind and orienting strategy accordingly. Asking about someone’s demographics or making an educated guess to use some witty humor and knowledge tends to impress more.
Helpful resources
Checkout Convokit